Motivation
2048 looks simple, but it’s a great testbed for RL: stochastic tile spawns, sparse/delayed rewards, and a long horizon. My goal was to build a clean environment, compare algorithms, and iterate on a reward that encourages long-term board health over short-term merges.
Repo Map
game_2048_env.py: Custom environment and game logictrain_sac_sb3.py: SAC training pipeline (SB3)train_a2c_sb3.py: A2C training pipeline (SB3)conf/train_sb3.yaml: Config for training runsuse_model.py: Load and run a trained agentplay_human.py: Play the game with keyboard controls
Journey
1) Building the Environment
I implemented a Gym-like environment that exposes a compact state and 4 discrete actions (up, down, left, right). The first milestone was getting the rules correct and efficient: merging tiles once per move, handling random spawns, and detecting terminal states.
Early board state visualizations.
2) Reward Shaping
Naive rewards (just using score increases) led to greedy behavior and early dead-ends. I iterated on a composite signal balancing immediate merges with long-term board health.
- Merges/Score: Reward tile merges to provide a dense learning signal.
- Empty Tiles: Encourage keeping space on the board for future moves.
- Monotonicity/Smoothness: Prefer ordered boards that reduce deadlocks.
- Death Penalty: Penalize terminal states to prefer survivability.
3) Algorithms & Training
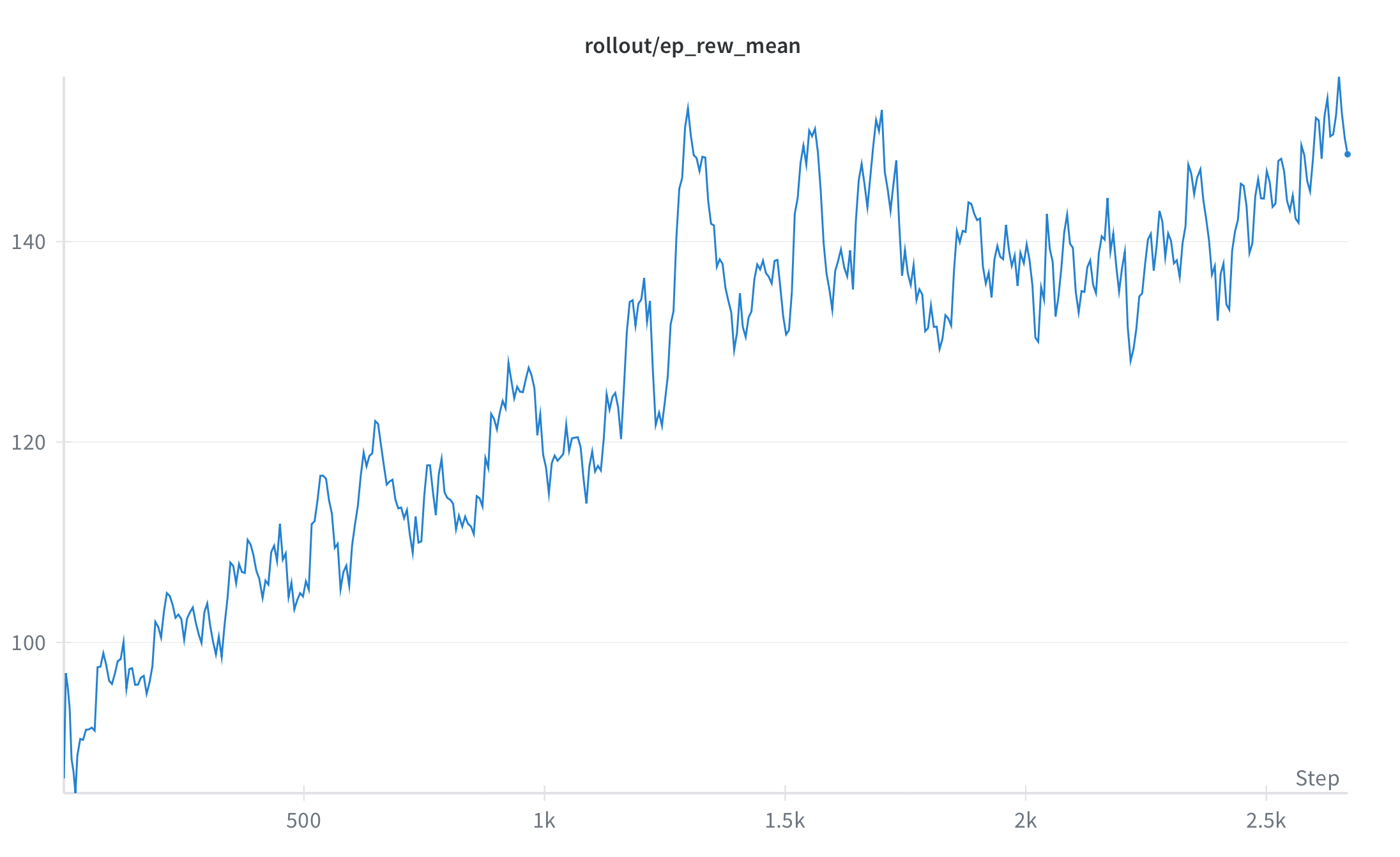
I compared A2C and SAC from Stable-Baselines3. A2C trained quickly but plateaued; SAC provided more stable improvements with the shaped reward. Runs were controlled via a YAML config.
4) Evaluation & Results
I evaluated using average episode score, peak tile, and survival length across multiple seeds.
- Peak Tile: 512
- Avg Score: 2500
- Survival Steps: 1000
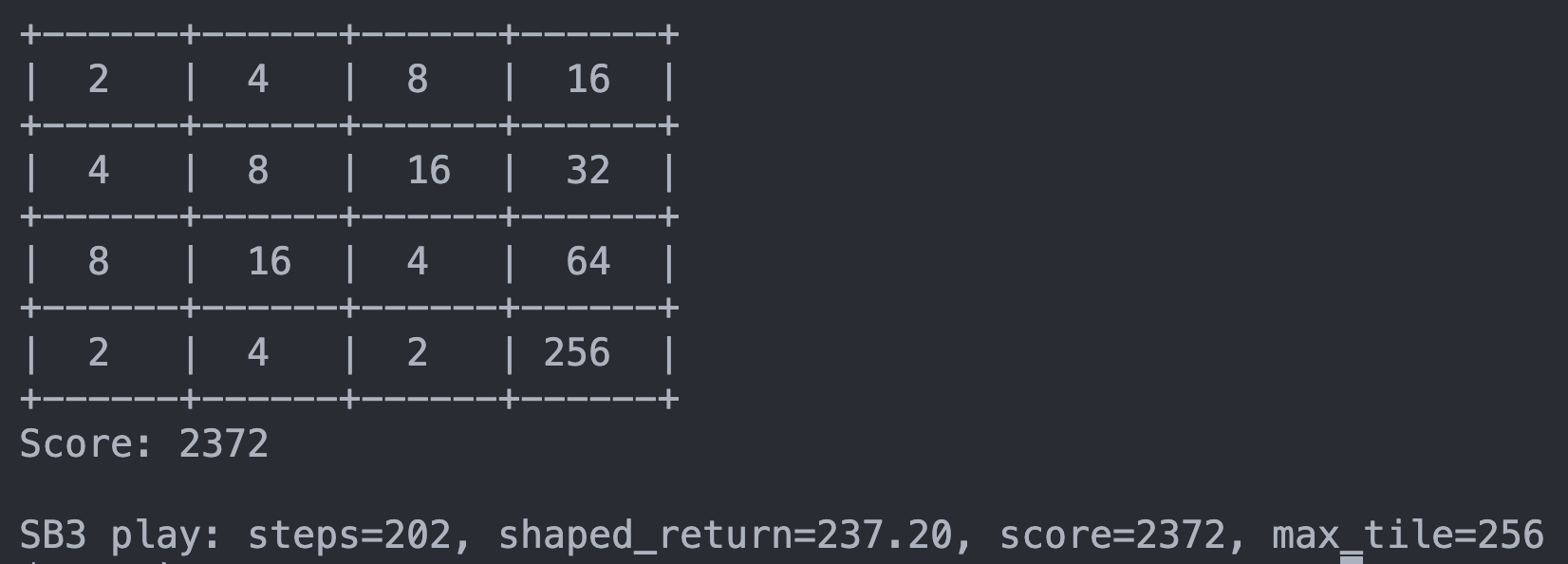
Example run: reached 256 here.
Hardships & Fixes
- Unstable Learning: Fixed by reward rebalancing and entropy tuning.
- Sparse Feedback: Added auxiliary signals for denser guidance.
- Exploration vs. Survival: Tuned action noise/entropy and terminal penalties.
- Overfitting Seeds: Evaluated across multiple seeds and tracked variance.
What I Learned
- Reward shaping can unlock learning when signals are sparse.
- Stability often beats peak performance for practical results.
- Clear evaluation (metrics + seeds) keeps progress honest.
- Small, testable changes beat sweeping rewrites.